Part of a series
Decisive AI & Governance
“The machines have the answers. You have the call.”
Career pillar
Can vs. Should: The One-Word Label That Fixes AI-Era Meetings
AI converts "should" questions into "can" questions without telling you. One labeling rule brings judgment back into AI-era meetings and governance forums.
There are two kinds of questions in this world, and the future of your leadership lives in the gap between them.
The first kind: Can we? Can we automate this process? Can we predict which customers will churn? Can we enter this market profitably? "Can" questions are questions of capability, feasibility, and probability. Their answers live in data — and AI is, without exaggeration, the greatest "can" machine ever built. It will answer "can" questions all day, faster and often better than your smartest analyst, and it will never once ask for a raise or eat the last donut in the break room.
The second kind: Should we? Should we automate this process, knowing it changes forty people's lives? Should we act on the churn prediction, knowing how it changes the way we treat customers? "Should" questions aren't about what's possible. They're about what's right, what's worth it, and what kind of organization — or person — you want to be.
"Should" questions require three things no model possesses: values, accountability, and the willingness to own consequences. A model can simulate values it found in training data. It cannot hold them, because holding a value means paying a price for it, and the model has nothing to pay with. It doesn't lose sleep. It doesn't face the team. It doesn't live in the world it recommends.
You do. That's not a limitation. That's the job.
The Optimization Trap
Here's where it gets subtle. The danger isn't that AI answers "should" questions badly. The danger is that it converts "should" questions into "can" questions without telling you.
Watch how it happens. A leadership team asks, "Should we restructure the service organization?" Somebody feeds the question to the platform. The platform — being a "can" machine — quietly translates it into the only kind of question it can answer: "What restructuring option maximizes the metrics I've been given?" Out comes a recommendation, polished and confident. The team reviews it, debates the details, approves a version of it.
Notice what never happened: nobody decided whether they should. The "should" got dissolved into the optimization, and the optimization got mistaken for the decision. The values question — what do we owe these people, what does this do to our culture — never made it into the room, because the model had no field for it.
A machine optimizes toward objectives. It cannot choose the objectives. The moment you let the optimizer pick the objective, you haven't automated the decision. You've abandoned it, with extra steps.
The one-word fix
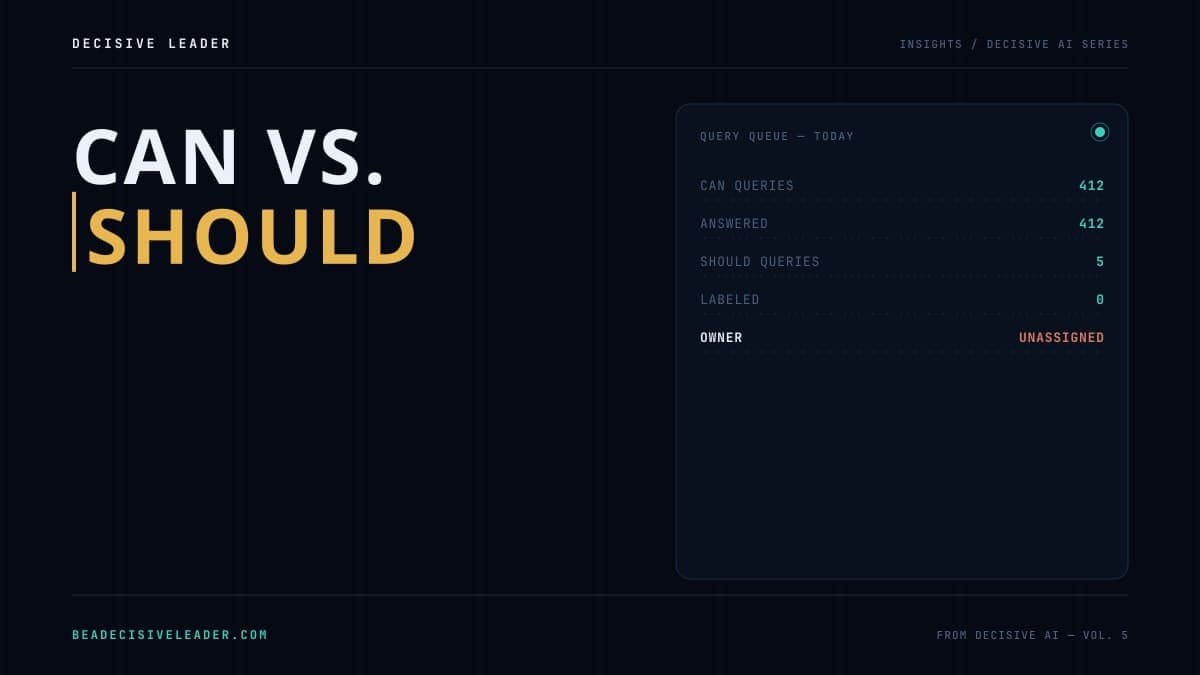
In Decisive AI, our test case Johnny audits a week of his team's AI queries and finds that roughly one in five is a "should" wearing a "can" costume. Should we sunset the legacy product — phrased as "model the sunset scenario." Should we reorganize the team — phrased as "what's the optimal org structure?" Each time, the team treats the output as if the hard part is done, when the hard part hasn't even started.
So Johnny institutes the simplest rule of his entire AI rollout:
Before any query goes to the model, label it. CAN or SHOULD.
CAN questions run freely — that's the machine doing exactly what machines do best. SHOULD questions can absolutely use the model's help for the analysis underneath, but they must come back to a named human, with the label still attached.
It's a piece of tape on a question. It costs nothing. And it changes everything, because the label does what labels do: it makes the invisible thing visible. The team stops accidentally laundering judgment calls through the analytics queue. Arguments come back to the conference room, where they belong.
One analyst called it the most annoying rule he's ever loved.
Try it this week
For one week, label every consequential query before it ships to any AI tool — yours included. Count how many SHOULDs were headed to the machine dressed as CANs. Most leaders find at least three.
Then decide who answers them. Because the machines have the answers. You have the call.
The full labeling discipline — plus the three-tier Decision Rights Charter that operationalizes it — is in Decisive AI, Vol. 5 of the Decisive Edge series. Get the books → Or pressure-test your current AI governance with the Tactical AI Audit.
Join The Bridge for one deployable protocol like this every Friday. Follow Decisive Leader on LinkedIn.
Was this piece useful?